Variable Compliance Control using RL
Solving peg-in-hole tasks with an uncertain goal pose.

Published by: Alishba Imran
Co-edited by: Anson Leung, William Ngo
In this blog, I’ll be covering the importance of compliance control (with a focus on force control), and how we can use a reinforcement learning based framework for position-controlled robot manipulators to solve contact-rich tasks. The proposed framework will be referenced from this research paper!
Background
Existing industrial robots are almost always programmed using a position control scheme where a prescribed trajectory in space has been pre-programmed before run-time. For more complex and precise applications, it becomes very important to precisely control the force applied by the end-effector rather than controlling the robots positioning.
Often external force is measured using a six-axis force/torque sensor which measures any force applied to the end-effector. The basic idea behind force control is simple: the output of the sensor is used to close the loop in the controller, adjusting each of the joint torque to match the desired output.
In reality, force control is not always as easy as that. Often problems will arise from the fact that the robot needs to perform a trajectory in certain directions while also having precise control of the forces in other directions.
Compliance Control
Compliance control allows us to minimize the impact during the collision of an end-effector with the contact environment. Active compliance control can be used to imitate human hand capability where force feedback is used to specifically generate compliance tasks at the robot endpoint.

Force control can be categorized into the following main categories:
→ Indirect force control (impedance): the objective of the impedance control is to realize the desired dynamic relationship between the end-effector position of the robot and the contact force. The performance of the impedance control depends on the impedance parameters, which come from the dynamics of the environment. The input of the impedance model is the position/velocity of the end-effector, and its output is the exerted force.
→ Direct force control: directly controlling the robot’s force in the Cartesian space or in the joint space.
→ Hybrid position/force control: the position and force are controlled in two separate channels with two control loops: the internal loop is the position control and the external loop is the force control. However, position-force control works best when the task is well-defined and in a well-known environment. It is often not available for complex tasks or might fall apart in less controlled environments.
Problem with Existing Active Compliance Control Methods
Existing active compliance control methods are not practical to use in real applications because model parameters need to be identified, and controller gains need to be tuned manually. Manually engineering for specific tasks requires a lot of time, effort, and expertise. These manual approaches are also not robust and aren’t effective for generalizing to variations in the environment.
To reduce human involvement and increase robustness to uncertainties, the most recent research has been focused on learning either from human demonstrations (some form of behavioral cloning or imitation learning) or directly from interactions with the environment through Reinforcement Learning (RL). I will be focusing on the latter, RL frameworks for position-controlled robot manipulators.
Peg-in-hole assembly task

Peg-in-hole is often a very complex but important assembly task. Within a peg-in-hole task, one of the components is grasped and manipulated by the robot manipulator, while the second component has a fixed position. The method that I’ll be speaking about was designed for a position-controlled robot manipulator with a force/torque sensor at its wrist. Typically, these insertion tasks can be divided into two main phases: search and insertion.
Search phase: the robot has to align the peg within a certain clearance region of the hole. The peg starts out at a distance from the center of the hole in a random direction. This distance from the hole is called the “positional error”.
Insertion phase: the robot adjusts the orientation of the peg with respect to the hole orientation to eventually push the peg to the desired position.
System Architecture
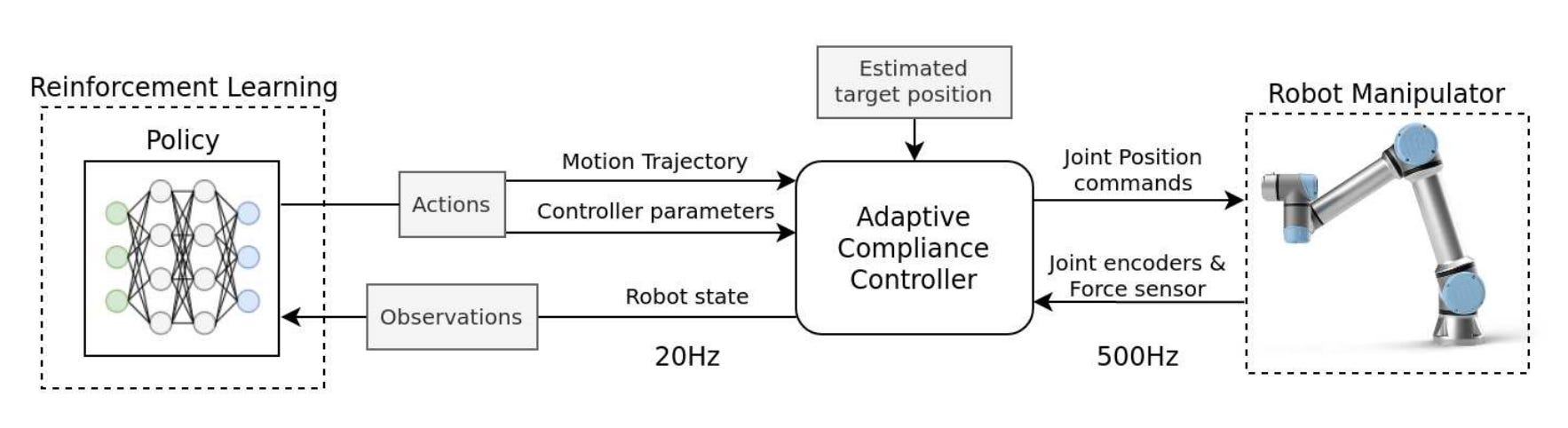
There are two control loops:
The inner loop: an adaptive compliance controller using a parallel position-force controller. This loop runs at a certain control frequency (i.e., 500 Hz which is the max. available in Universal Robots e-series robotic arms).
The outer loop: an RL control policy provides subgoal positions and the parameters of the compliance controller. It runs at a lower control frequency than the inner loop (i.e., 20 Hz) which allows for the policy to have enough time to process the robot state and compute the next action to be taken by the manipulator. At the same time, the inner loop’s precise high-frequency control would seek to achieve and maintain the subgoal provided by the policy.
The input to the overall system is the estimated target position and orientation for the insertion task.
Soft Actor Critic (SAC)
In terms of the RL algorithm, we can use soft actor critic (SAC) because it has high sample efficiency which is ideal for real-life robotic applications. SAC is a deep off-policy actor-critic RL algorithm based on maximal entropy.
Entropy-Regularized RL
To understand SAC, it’s important to understand the entropy-regularized RL setting where there are slightly different equations for value functions.
In RL, entropy refers to how predictable the actions are of an agent. This is also closely related to the certainty of its policy on which action will yield the highest reward in the long run: if certainty is high, entropy is low, and if certainty is low then entropy is high.
As the agent is learning its policy and an action returns a positive reward for a state, the agent might always use this action in the future because it knows it produced some positive reward. This isn’t effective though because there could be another action that yields a much higher reward, but the agent will never try it because it will just exploit what it has already learned. This means that the agent can get stuck in a local optimum because it has not fully explored the behavior of other actions and has not found the global optimum as a result.
This is where entropy can be very useful because we can use entropy to encourage exploration and avoid getting stuck in local optima. The maximum-entropy RL objective can be defined as:
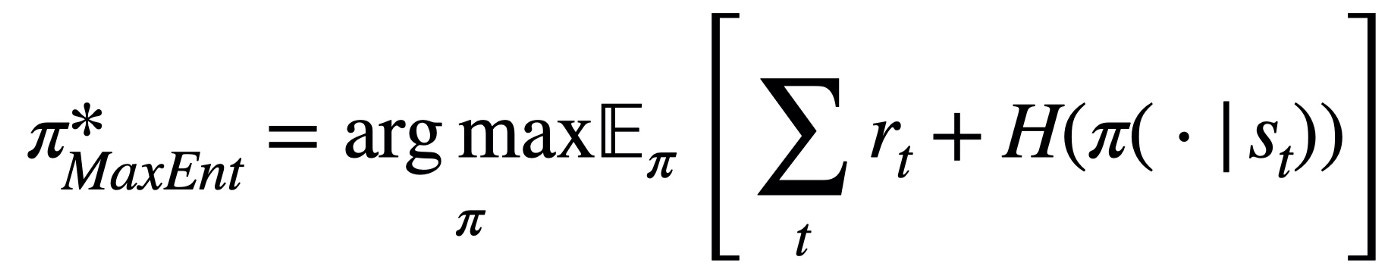
SAC itself aims to maximize the expected reward while also optimizing maximal entropy. The SAC agent will optimize for a maximal-entropy objective, due to a temperature parameter α introduced in the paper, that encourages exploration. The core idea of this method is to succeed at the task while acting as randomly as possible. SAC is an off-policy algorithm which is why it uses a replay buffer to reuse information for more sample-efficient training.
The distributed prioritized experience replay approach can also be used here for further improvement.
Multimodal Policy
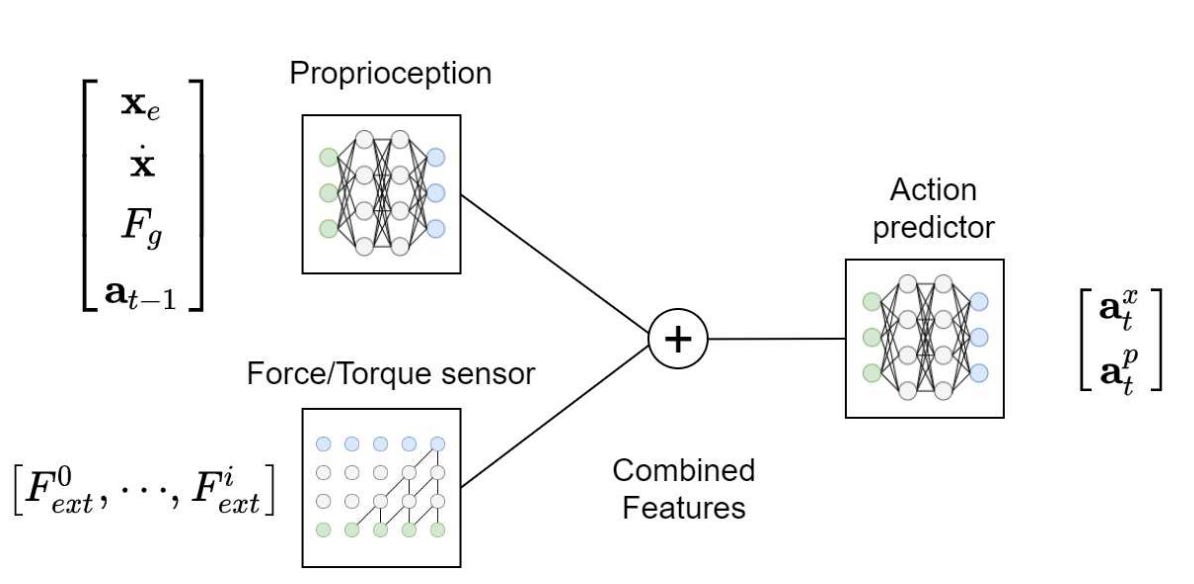
The control policy input is the robot state and the robot state includes the proprioception information of the manipulator and haptic information.
This proprioception information includes the pose error between the current robot’s end-effector position and predicted target pose, end-effector velocity, desired insertion force, and actions taken in the previous time step.
For force-torque feedback, the last 12 readings from the six-axis force/torque sensor, as a 12 x 6 time series are used:
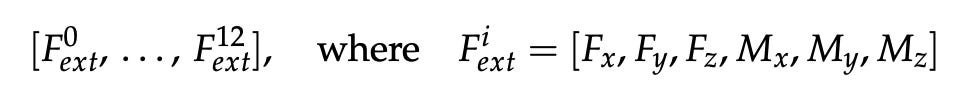
Compliance Control Scheme
This method uses a common force-control scheme combined with a RL policy to learn contact-rich manipulations for a rigid position-controlled robot.
The inputs into the model are the estimated goal position, policy actions, and the desired contact force. The controller then outputs the joint position commands for the robotic arm.
Specifically, a PID parallel position-force control is used alongside a selection matrix for the degree of the control of position and force over each direction.
Here is a scheme of what this looks like:

Reward Function
For all tasks, the reward function used was:

where Fg is the desired insertion force, Fext is the contact force, and Fmax is the defined allowed maximal contact force.
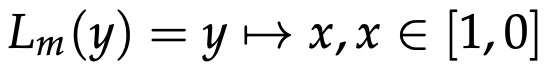
is a linear mapping in the range 1 to 0. This means that the closer to the goal and the lower the contact force, the higher the obtained reward.
You can also add a collision constraint into this framework through adding a penalty (giving it a negative reward and finishing the episode early) for the agent if it collides with the environment. In this scenario, collision was defined as exceeding the force limit or Fmax. This collision constraint overall encourages a much safer exploration which is why it’s key.
Future Work
The policy explored in this paper was able to correctly learn the nominal trajectory and the appropriate force-control parameters to succeed at the peg-in-hole task. The policy also achieved a high success rate under varying environmental conditions in terms of the uncertainty of goal position, environmental stiffness, and novel insertion tasks.
Although SAC was used in this example because of its sample efficiency as an off-policy algorithm, we can also test out the advantages of other learning algorithms using a very similar overall framework.
More Resources
If you’re interested in this area of research, you can check out some of these research papers for other approaches explored in the industry:
Feedback Deep Deterministic Policy Gradient With Fuzzy Reward for Robotic Multiple Peg-in-Hole Assembly Tasks: learning dual peg insertion by using deep deterministic policy gradient (DDPG) with a fuzzy reward system.
Learning variable impedance control: using an RL algorithm call-policy improvement with path integrals (PI2).
Adaptation of manipulation skills in physical contact with the environment to reference force profiles: learning method based on iterative learning control (ILC).
Thanks for checking out this blog! If you’re interested in keeping up with future pieces we write, please consider subscribing.
About Us
Welcome to ML Reading Group! We’re a group of students, researchers, and developers sharing our learnings from the latest ML and robotics research papers on topics such as Bayesian Optimization, Active Learning, Reinforcement Learning, Imitation Learning, Time Series Models, and much more!
Our group currently consists of:
Alishba Imran: worked as an ML Developer at Hanson Robotics to develop Neuro-Symbolic AI, RL, and Generative Grasping CNN approaches for Sophia the Robot. Applied this work with a masters student and professor at San Jose State University, with support from the BLINC Lab, to reduce cost of prosthetics from $10k to $700, and make grasping more effecient. Currently, the co-founder of Voltx and working on RL and Imitation Learning techniques for machine manipulation tasks at Kindred.Ai.
William Ngo: previously worked as a Research Intern at Canada Excellence Research Chair to apply Deep Learning methods to help solve mathematical optimization problems. Also worked as a Data Science Consultant at Omnia AI, Deloitte Canada's AI Practice. Currently, an MSc Computer Science Student at the University of Toronto and an AI Engineering Intern at Kindred.Ai.
Anson Leung: worked on a cloud computing platform and recognition computing at IBM, and as a Software Engineer at Oursky. Currently, completing his MSc in Applied Computing at the University of Toronto.
You can get in touch with us here anytime: