Meta-Imitation Learning for Demonstrating New Tasks
Few-shot learning

Published by: Alishba Imran
Co-edited by: Anson Leung, William Ngo
Most robots and machines need to perform a wide range of tasks for which they have to be able to learn a wide variety of skills quickly and efficiently.
Current, DNNs allow for methods to represent these complex skills, but learning each of these skills from scratch becomes unscalable and infeasible.
In this blog:
I break down imitation learning and key areas within it
I will be looking at a meta-imitation learning method (inspired by this paper) that enables a robot to more efficiently learn, allowing it to acquire new skills from a few or just a single demonstration.
Imitation Learning
With imitation learning the robot learns manipulation by observing the expert’s demonstration, and skills. Then it tries to generalize these to other unseen scenarios. This process allows for learning the behavior, learning about the surrounding environment, and learning the mapping between the observation and the performance.
Currently, the main methods of imitation learning can be divided into behavior cloning (BC), inverse reinforcement learning (IRL), and generative adversarial imitation learning (GAIL):
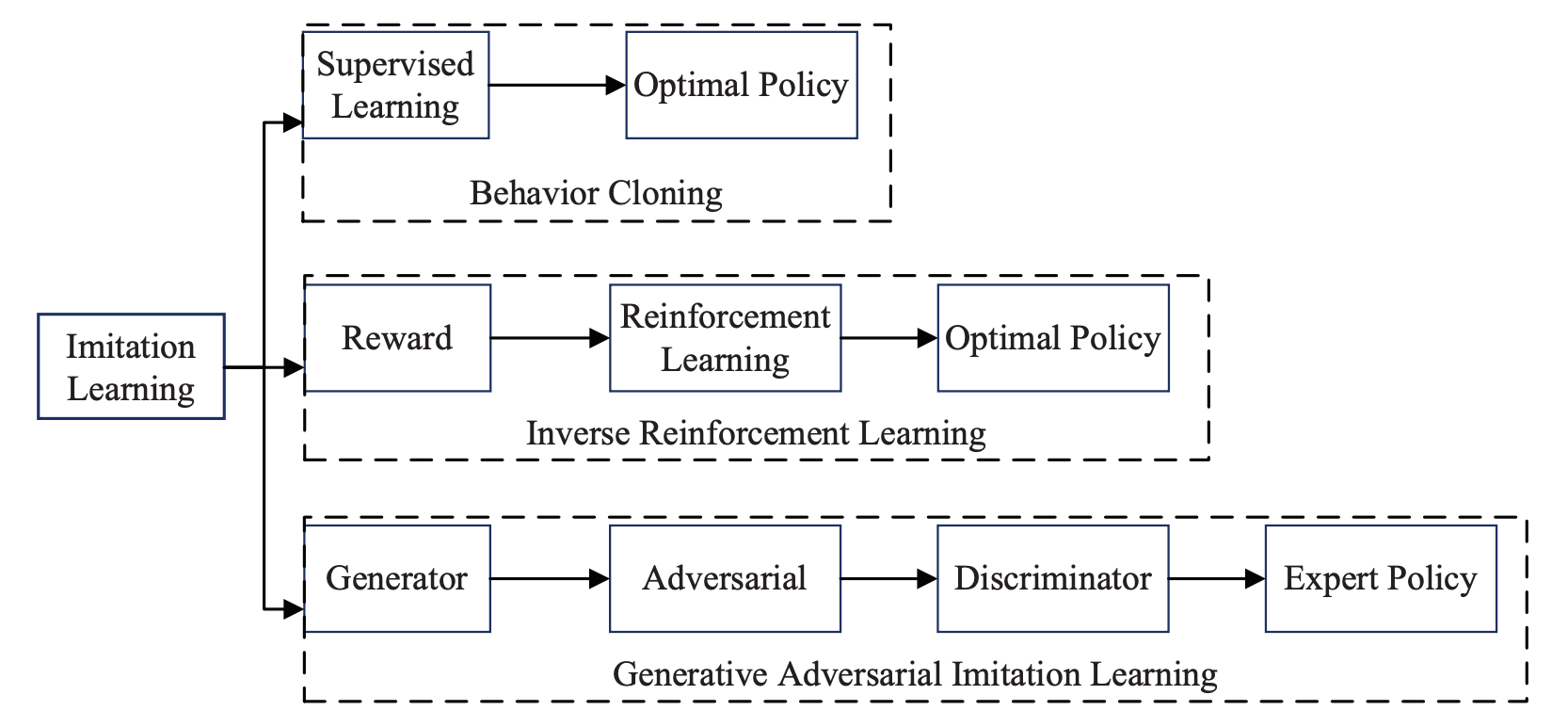
BC and IRL form the main buckets of imitation learning methods that I’ll be breaking down further.
Behavioral cloning (BC)
BC utilizes direct policy learning where a policy is learned that directly maps from the input to the action/trajectory.
Lets say you have a dataset of demonstrated trajectories with state-action pairs and contexts:

It is possible here to directly compute a mapping from states and/or contexts to control inputs as:

This kind of policy can usually be given through most standard supervised learning methods.
The problem with BC is that when the number of samples is not enough, the agent cannot learn situations that are not included in samples (not generalizable). In order to solve the learning problem of insufficient samples, the method of IRL can be used.
Inverse Reinforcement Learning (IRL)
Compared to methods of BC, IRL is more adaptable in responding to different environments. With BC, when the execution environment or robot model changes significantly, the resulting mapping function will be difficult to apply and will need to be learned again.
On the other hand, IRL is a method of evaluating how well an action is performed via a reward function (which is an abstract description of behavior).
Given a reward signal, a policy can be obtained to maximize the expected return. This policy can be expressed as:

In this scenario, the reward function is considered unknown and needs to be recovered from expert demonstrations under the assumption that the demonstrations are (approximately) optimal with respect to this reward function.
The key barrier is that learning policies from imitation learning require a large number of demonstrations.
Meta-imitation learning can be used to overcome this challenge as it leverages data from previous tasks in order to learn a new task from one or a few demonstrations.
Meta-Learning
The entire aim of meta-learning is to learn new tasks from very little data. To achieve this, a meta-learning algorithm can first meta-train on a set of tasks {Ti}, called the meta-train tasks.
We then evaluate how quickly the meta-learner can learn an unseen meta-test task Tj. We typically assume that the meta-train and meta-test tasks are drawn from some unknown task distribution p(T). Through meta-training, a meta-learner can learn some common structure between the tasks in p(T) which it can use to more quickly learn a new meta-test task.
Few-Shot Meta-Learning
The goal of few-shot meta-learning is to train a model that can quickly adapt to a new task using only a few data points and training iterations. To accomplish this, the model or learner is trained during a meta-learning phase on a set of tasks, such that the trained model can quickly adapt to new tasks using only a small number of examples or trials.
Policies and Training
This paper aims to develop a method that can learn to learn from both demonstration and trial-and-error experience. This is done in two phases:
meta-learn a Phase I policy that can gather information about a task given a few demonstrations.
meta-learn a Phase II policy that learns from both demonstrations and trials produced by the Phase I policy.
Vision-based architectures are used during both Phase I and Phase II. In this scenario, few-shot learning is being utilized by explicitly meta-training Phase I and Phase II policies to learn from very little demonstration and trial data.
Phase I policy is written as:

where θ represents all the learnable parameters.
Phase II policy is written as:

One common approach would be to use a single model across both phases such as using a single MAML (Finn et al., 2017) policy that sees the demonstration, executes trial(s) in the environment, and then adapts its own weights from them. However, a key limitation in using this type of a single model is that updates after the trials will also change behavior during the trials.
Instead, they represent and train separately. This ensures that the distribution of trial data for each task remains stationary. They first train:

by freezing its weights, and collecting trial data:
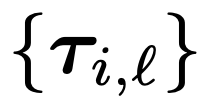
from the environment for each meta-training task.
They train each of these policies with off-policy demonstrations and trial data using Thompson sampling which acts highly according to the policy’s current belief of the task.
Watch-Try-Learn (WTL) Approach
The WTL approach demonstrates the task and then observes and critiques the performance of the agent on the task (if it initially fails). This is done by demonstrations and trials in the inner loop of a meta-learning system, where the demonstration guides the exploration process for subsequent trials, and the use of trials allows the agent to learn new task objectives that it might not have seen during meta-training.
Future Work
There’s a lot of exciting research happening in this space to develop more robust One-Shot and Few-Shot learning methods that can be extended to a broad range of tasks. If you’re interested in diving deeper, I would recommend checking out these papers:
“Task-Embedded Control Networks for Few-Shot Imitation Learning”
“One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”
Thanks for checking out this blog! If you’re interested in keeping up with future pieces we write, please consider subscribing.
About Us
Welcome to ML Reading Group! We’re a group of students, researchers, and developers sharing our learnings from the latest ML and robotics research papers on topics such as Bayesian Optimization, Active Learning, Reinforcement Learning, Imitation Learning, Time Series Models, and much more!
Our group currently consists of:
Alishba Imran: worked as an ML Developer at Hanson Robotics to develop Neuro-Symbolic AI, RL, and Generative Grasping CNN approaches for Sophia the Robot. Applied this work with a masters student and professor at San Jose State University, with support from the BLINC Lab, to reduce cost of prosthetics from $10k to $700, and make grasping more effecient. Currently, the co-founder of Voltx and working on RL and Imitation Learning techniques for machine manipulation tasks at Kindred.Ai.
William Ngo: previously worked as a Research Intern at Canada Excellence Research Chair to apply Deep Learning methods to help solve mathematical optimization problems. Also worked as a Data Science Consultant at Omnia AI, Deloitte Canada's AI Practice. Currently, an MSc Computer Science Student at the University of Toronto and an AI Engineering Intern at Kindred.Ai.
Anson Leung: worked on a cloud computing platform and recognition computing at IBM, and as a Software Engineer at Oursky. Currently, completing his MSc in Applied Computing at the University of Toronto.
You can get in touch with us here: